
Τα Μεγάλα Γλωσσικά Μοντέλα (LLMs) -προηγμένα συστήματα τεχνητής νοημοσύνης (AI) που χρησιμοποιούν νευρωνικά δίκτυα με δισεκατομμύρια παραμέτρους για την επεξεργασία, κατανόηση και δημιουργία φυσικής γλώσσας- έρχονται όλο και πιο συχνά στο προσκήνιο ως δυνητικοί «βοηθοί» στη λήψη κλινικών αποφάσεων. Το κρίσιμο ερώτημα, όμως, είναι αν μπορούν να σταθούν εκεί όπου ο χρόνος μετράει: Στη διαλογή των ασθενών στα Τμήματα Επειγόντων Περιστατικών (ΤΕΠ), δηλαδή στην πρώτη εκτίμηση του πόσο επείγον είναι ένα περιστατικό και πού πρέπει να κατευθυνθεί.
Σ’ αυτό το ερώτημα επιχειρεί να απαντήσει μεγάλη αναδρομική μελέτη από πανεπιστημιακό νοσοκομείο της Θεσσαλονίκης, η οποία υπέβαλε τα γλωσσικά μοντέλα σε «τεστ πραγματικής ζωής», συγκρίνοντας τις απαντήσεις τους με τις αποφάσεις γιατρών που έκαναν τη διαλογή.
Τι έδειξε η ανάλυση
Οι ερευνητές ανέλυσαν 39.375 ανώνυμα περιστατικά από το ΤΕΠ του Πανεπιστημιακού Γενικού Νοσοκομείου ΑΧΕΠΑ, κατά την περίοδο Ιουνίου 2024 – Ιουλίου 2025. Κάθε περιστατικό είχε ήδη ταξινομηθεί από γιατρούς με βάση τον Emergency Severity Index (ESI), ένα σύστημα διαλογής 5 επιπέδων, όπου στόχος είναι να ξεχωρίσουν γρήγορα τα πραγματικά από τα λιγότερο επείγοντα περιστατικά.



Στη συνέχεια, τα ίδια κλινικά στοιχεία (ηλικία, συμπτώματα, και όπου υπήρχαν καταγραφές, ζωτικά σημεία/επίπεδο συνείδησης) μετατράπηκαν σε τυποποιημένα «περιστατικά» και δόθηκαν σε 7 διαφορετικά γλωσσικά μοντέλα [ChatGPT-5 (Thinking), ChatGPT-5 (Instant), Gemini 2.5, Qwen 3, Grok 4.0, DeepSeek v3.1, Claude Sonnet 4], χωρίς ειδική εκπαίδευση ή προσαρμογή. Ζητήθηκε από τα μοντέλα να δώσουν:
- βαθμό ESI,
- κλινική παραπομπής (από προκαθορισμένη λίστα ειδικοτήτων),
- εκτίμηση για το αν χρειάζεται εισαγωγή.
Πόσο «συμφώνησαν» τα μοντέλα με τους γιατρούς
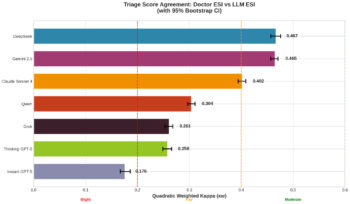
Στο βασικό ζητούμενο – δηλαδή τη βαθμολογία ESI – κανένα μοντέλο δεν έφτασε επίπεδα συμφωνίας που να θεωρούνται ασφαλή για αυτόνομη χρήση. Τα καλύτερα μοντέλα κινήθηκαν σε μέτρια συμφωνία με τις ιατρικές αποφάσεις, ενώ άλλα έπεσαν σε χαμηλότερα επίπεδα.
Επίσης, τα μοντέλα έτειναν να «υπερ-διαλέγουν» (να αξιολογούν δηλαδή τα περιστατικά ως πιο επείγοντα σε σχέση με τους γιατρούς). Μπορεί αυτό να ακούγεται «ασφαλές», όμως όταν ένα Τμήμα Επειγόντων Περιστατικών είναι υπό πίεση, η αυξημένη ροή θα κοστίσει σε χρόνο και πόρους.
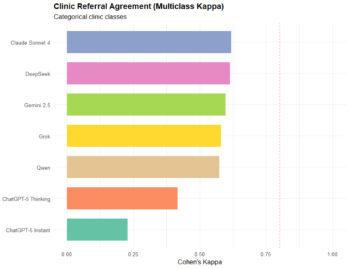
Παραπομπή σε κλινική: Καλύτερα αποτελέσματα, αλλά όχι «άριστα»
Στο δεύτερο σκέλος – την επιλογή της κατάλληλης κλινικής – ορισμένα μοντέλα είχαν σαφώς καλύτερη εικόνα απ’ ό,τι στο ESI, με τις κορυφαίες επιδόσεις να πλησιάζουν τις 2/3 σωστές επιλογές.
Η μελέτη δείχνει ότι τα γλωσσικά μοντέλα λειτουργούν πιο αξιόπιστα όταν το σενάριο είναι «καθαρό», δηλαδή εμπεριέχει περιστατικά που κάνουν οφθαλμοφανές το σε ποια ειδικότητα ταιριάζουν (π.χ. οφθαλμολογικά, παιδιατρικά, ΩΡΛ). Αντίθετα, δυσκολεύονται εκεί όπου η απόφαση εξαρτάται περισσότερο από την εκτίμηση βαρύτητας, την σύνθεση ζωτικών σημείων ή τις λεπτές κλινικές «αποχρώσεις».
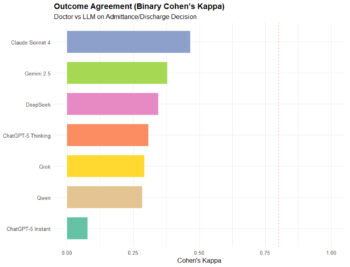
Πρόβλεψη εισαγωγής: Οι «επικίνδυνες» κλίσεις
Η τρίτη δοκιμασία – αν θα χρειαστεί εισαγωγή – είναι από τις πιο «ευαίσθητες», γιατί τα λάθη δεν είναι ισοδύναμα. Όπως εξήγησαν οι ερευνητές, «είναι άλλο να κάνει κανείς μια «περιττή» εισαγωγή κι άλλο να χάσει έναν ασθενή που έπρεπε να μείνει».
Στη μελέτη, το καλύτερο μοντέλο είχε μέτρια αξιοπιστία στην πρόβλεψη εισαγωγής, με σχετικά ισορροπημένη εικόνα ανάμεσα σε ευαισθησία και ειδικότητα. Άλλα μοντέλα, ωστόσο, έδειξαν έντονες συστηματικές μεροληψίες. Κάποια «επέλεγαν» την εισαγωγή πιο εύκολα (υπερ-εισαγωγές), ενώ ένα από τα μοντέλα εμφάνισε το αντίθετο προφίλ (χαμηλή ευαισθησία), κάτι που στην πράξη μεταφράζεται σε αυξημένο κίνδυνο «να φύγει για το σπίτι» ασθενής που δεν πρέπει.
Συμπέρασμα
Όπως φαίνεται από την παρούσα μελέτη, τα γλωσσικά μοντέλα μπορούν να παίξουν σημαντικό ρόλο ως υποστηρικτικά εργαλεία, όχι όμως ως αυτόνομα συστήματα διαλογής. Με άλλα λόγια, μπορούν να βοηθήσουν:
- ως ένα «δεύτερο ζευγάρι μάτια» σε τυποποιημένα σενάρια,
- ως εργαλείο που προτείνει πιθανή κλινική/ροή ή
- ως σύστημα που οργανώνει πληροφορίες.
Όμως, η τελική κρίση – ειδικά στη βαρύτητα και στην απόφαση εισαγωγής – δεν μπορεί ακόμη να μεταφερθεί με ασφάλεια από έναν πραγματικό γιατρό σ’ ένα μοντέλο τεχνητής νοημοσύνης.
Διαβάστε επίσης
Πόσο «δικός» μας είναι o εγκέφαλος με νευροεμφυτεύματα; Διλήμματα και κίνδυνοι της Νευροτεχνολογίας
Πόσο έτοιμη είναι η Τεχνητή Νοημοσύνη για να μπει στο χειρουργείο; Τα δεδομένα δείχνουν προβλήματα
Το ChatGPT γίνεται ο νέος «προσωπικός γιατρός» – Τι σημαίνει αυτή η εξέλιξη



